We think the most useful place for human intervention is between the two stages: after candidate term generation, but before full extraction begins.
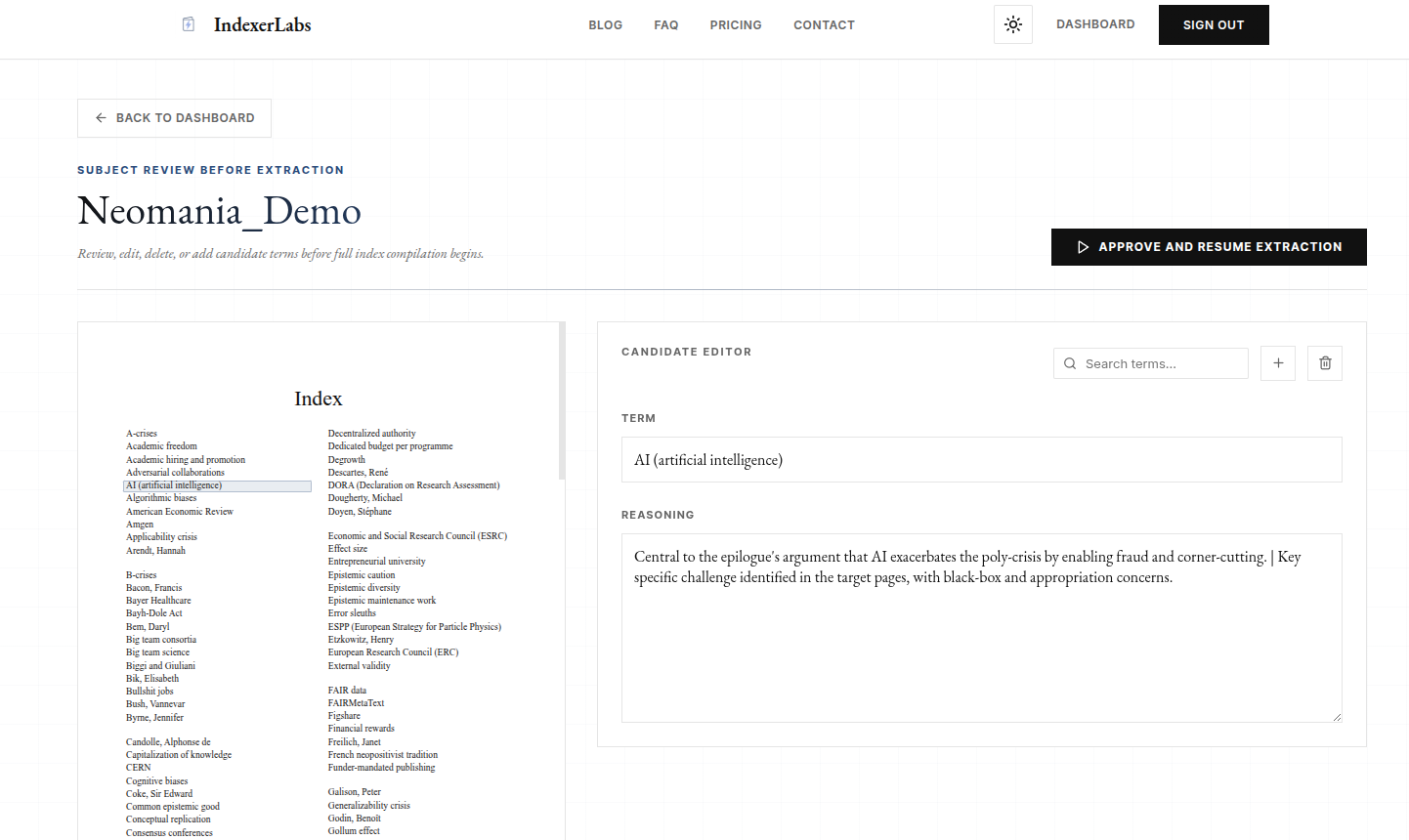
Today, we’re introducing a new review step inside the IndexerLabs subject indexing pipeline: Checkpoints.
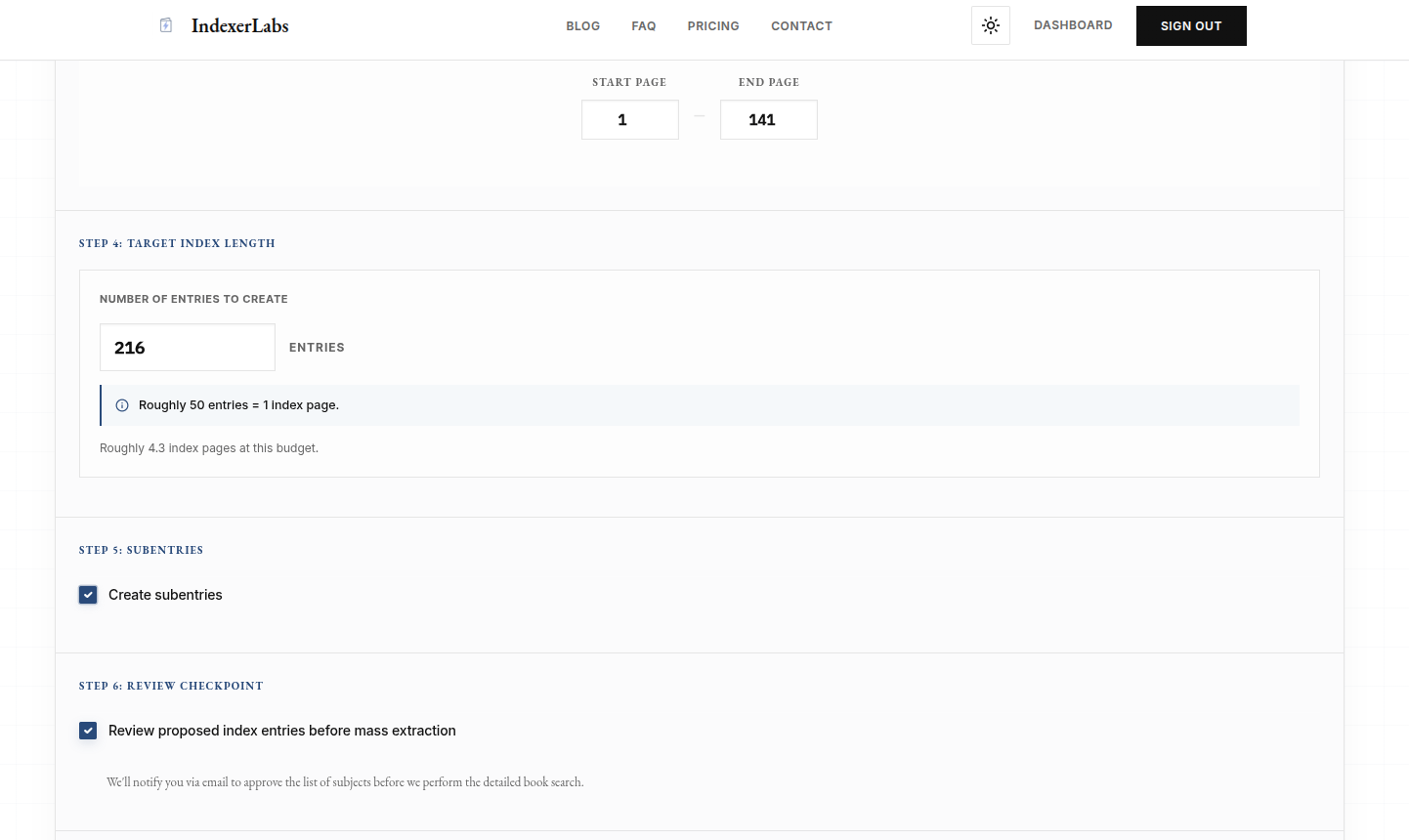
At that stage, the candidate pool already exists. The system has already done the discovery work. It has proposed the headings that it believes belong in the index.
The expensive extraction stage has not yet run across the entire reviewed list.
That gives the reviewer a high-leverage moment to improve the index before the rest of the pipeline commits to a final set of entries.
The reviewer can:
- remove weak or unnecessary headings
- add missing terms
- adjust phrasing
- narrow or broaden the scope of the draft
- improve the quality of the downstream extraction stage
This is very different from cleaning up a finished AI output after the fact.
With Checkpoints, the reviewer intervenes while editorial judgment still has the greatest effect on the final index. The system proposes a candidate structure, the human can refine that structure, and the downstream pipeline then performs the extraction, verification, and delivery work against the approved list.
A better workflow for an AI book indexing tool
We think this creates a better workflow for automated book indexing.
A weak automated book indexing workflow forces the human to repair a bloated final draft after the most important decisions have already been made.
A stronger AI book indexing tool lets the human intervene earlier, while the entry list is still editable and before locator extraction has begun. This is human-in-the-loop indexing at its best: the reviewer is placed where their judgment has the greatest leverage over the final index.
That is what Checkpoints are designed to do.
Once the reviewed list is approved, the pipeline continues using that revised set of entries. The system then performs the extraction, verification, and delivery work needed to turn that editorially reviewed candidate list into a finished back-of-book index.
This means the human and the system are not doing the same job.
The model proposes what should be indexed.
The reviewer can correct, add, remove, and reshape the candidate list.
The extraction and delivery system then handles the mechanical problem of indexing that material correctly.
AI book indexing should separate judgment from extraction
We think this is a more realistic way to build an AI book indexing tool.
The editorial problem and the extraction problem are different enough that they should be handled as different stages in the workflow.
The first stage is about significance, omission, phrasing, and selection.
The second stage is about locators, verification, and reliable output.
A strong automatic book indexing system should be able to do both.
That is the direction we have been building toward across the platform: better editorial judgment through IndexLM-1.0, stronger locator verification through structured extraction, production-safe delivery through embedded DOCX support, and cleaner manual oversight through features like Quick Check and Checkpoints.
A good AI book indexing tool must know what to index.
Then it must index it correctly.
Checkpoints sit directly between those two problems, and we think they make the entire automated book indexing workflow stronger.
How do I use checkpoints?
To use checkpoints, ensure that the “Review proposed index entries before mass extraction” option is enabled during job creation.