AI for Book Indexing
Creating a high-quality book index has traditionally been one of the most time-consuming parts of publishing a nonfiction book. A good back-of-book index requires more than finding repeated words. It requires judgment: deciding which people, concepts, places, arguments, and themes matter enough to be included, how those entries should be phrased, when subentries are useful, and which page references actually help the reader.
IndexerLabs is an AI book indexing tool built for authors, publishers, editors, and scholarly presses that need a professional back-of-book index without waiting weeks or manually building one from scratch.
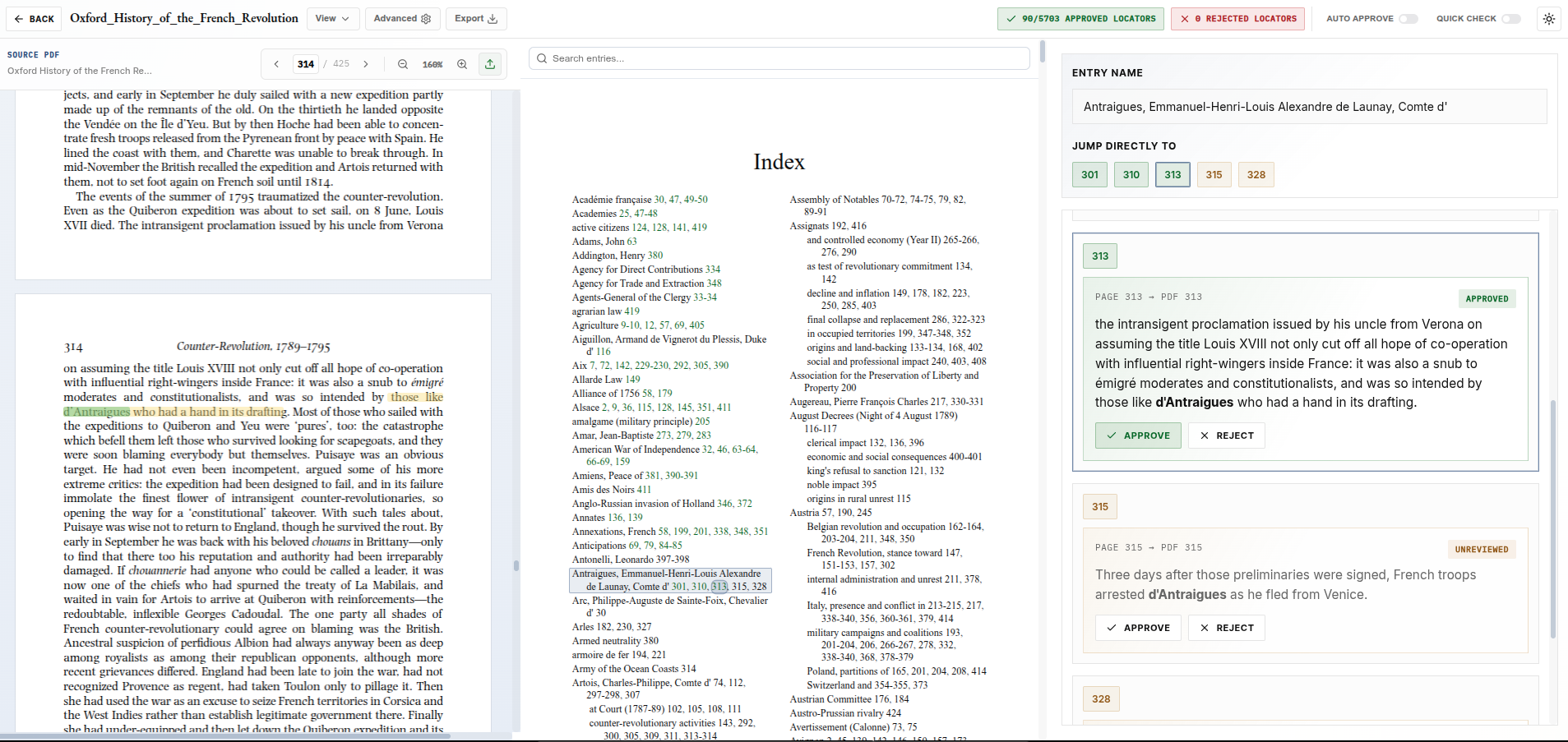
View a side-by-side comparison of a professional human index versus our AI-generated output for a 425-page scholarly volume.
View Oxford History Demo →AI for book indexing is changing how authors, publishers, editors, and scholarly presses create back-of-book indexes.
For many books, the index is one of the last production tasks before publication. It is also one of the most tedious. A good index requires close reading, editorial judgment, accurate page references, consistent phrasing, useful subentries, and careful review. For a full-length nonfiction or scholarly book, that can mean days or weeks of work.
IndexerLabs was built to make that process faster, more affordable, and easier to review.
Our approach to AI for book indexing is simple: a professional index should be treated as a structured editorial product, not as a loose list of keywords. That means an AI indexing system needs to know what belongs in the index, where those topics appear, how entries should be phrased, when subentries are useful, and how the final index will fit into a real publishing workflow.
What Is AI for Book Indexing?
AI for book indexing means using artificial intelligence to help create a back-of-book index from a manuscript.
At the simplest level, AI can identify repeated names, places, phrases, and concepts. That can be useful for brainstorming, but it is only the beginning. A professional book index requires much more than extraction.
A strong AI book indexing system should be able to:
- identify important topics, people, places, works, arguments, and themes
- distinguish substantive discussion from passing mention
- select useful entries rather than every repeated phrase
- merge duplicates and variant phrasings
- create top-level entries and subentries
- assign accurate locators
- support review and correction
- export the final index in a publisher-friendly format
That is the difference between AI keyword extraction and AI for book indexing.
A keyword extractor asks, “What words appear in this book?”
A real indexing system asks, “What would a reader reasonably expect to find in the index, and which pages would actually help them?”
Why Book Indexing Is Hard
Book indexing is difficult because it is partly mechanical and partly editorial.
The mechanical side involves finding where topics appear. If an entry refers to “John Adams,” the index needs to point to the pages where John Adams is actually discussed. If an entry refers to “natural law,” the locator should lead readers to a meaningful treatment of natural law, not merely a stray sentence where the phrase happens to appear.
The editorial side is harder. A good index is selective. It does not include every noun in the book. It does not include every repeated phrase. It does not send readers to long, unstructured strings of page numbers. It represents the book’s structure in a way that helps readers navigate.
For example, if a book is about the French Revolution, the phrase “French Revolution” may appear throughout the manuscript. Listing every page where the phrase appears would not create a useful index entry. A better index would organize the discussion into more specific topics: causes, constitutional reform, violence, monarchy, republicanism, military campaigns, popular sovereignty, and so on.
This is why AI for book indexing needs more than raw language fluency. It needs a workflow designed around indexing judgment.
AI for Book Indexing vs. ChatGPT
Many authors first ask whether they can simply upload a manuscript to ChatGPT and ask for an index.
For a short document, a general-purpose chatbot may be able to suggest possible index terms. For a full-length book, however, the problem becomes much harder.
A serious nonfiction manuscript may contain 80,000, 100,000, or 150,000 words. Once front matter, notes, bibliography, formatting, prompts, and output are included, the indexing task becomes too large and too structured for a single generic prompt.
Even when a model can technically accept a long manuscript, book indexing still requires consistency across the entire work. A useful index must preserve coverage from the beginning, middle, and end of the book. It must maintain consistent phrasing. It must avoid hallucinated page references. It must decide which topics deserve entries and which do not.
That is why IndexerLabs does not treat AI for book indexing as a one-prompt problem.
Instead, we use a staged workflow designed specifically for back-of-book indexes.
How IndexerLabs Uses AI for Book Indexing
IndexerLabs breaks the indexing process into separate stages.
Rather than asking one model to produce a complete index in one step, the system works through the manuscript in a structured pipeline. Each stage handles a different part of the indexing problem.
A typical workflow includes:
- Candidate discovery
The system identifies people, places, concepts, events, works, organizations, arguments, and themes that may belong in the index - Editorial selection
The system narrows the candidate pool toward the entries most likely to be useful to readers. - Entry refinement
Duplicate headings are merged, variant phrasings are normalized, and weak entries are removed. - Subentry generation
Broad entries are divided into meaningful subentries so readers are not left with long strings of page numbers. - Locator extraction
The system finds where each entry is actually discussed in the manuscript. - Verification
Locator claims are checked against textual evidence from the source document. - Review
Authors, editors, publishers, or indexers can inspect and revise the result. - Export
The final index is returned in a usable format, including workflows for Word documents.
This staged approach makes the index easier to control, easier to inspect, and easier to trust.
Why Specialized AI Matters
General-purpose AI models are trained for broad conversation, reasoning, and writing. They can be useful, but professional subject indexing is a specialized editorial task.
IndexerLabs uses IndexLM-1.0, a model trained on more than 1,000 real-world back-of-book indexes. The purpose is to teach the model the patterns of professional indexing: what gets included, what gets omitted, how entries are phrased, how broad topics are organized, and how much compression is appropriate for a finished index.
This matters because book indexing is full of judgment calls.
A good indexer constantly asks questions like:
- Is this topic important enough to include?
- Is this a main entry or a subentry?
- Should this be merged with another term?
- Is this phrase the one readers are most likely to search for?
- Does this page contain a meaningful discussion or only a passing mention?
- Is the index becoming too long?
- Are there too many weak entries?
- Does the final structure help readers navigate the book?
Those decisions are difficult to compress into a single prompt. A purpose-trained indexing model gives an AI book indexing system a stronger foundation. In our public experiment indexing the same book 120 times, IndexerLabs showed substantially stronger overlap with the human index than leading general-purpose AI models, offering empirical evidence that specialized indexing models are better suited to the editorial judgment required for professional book indexes.
AI for Book Indexing Should Separate Judgment from Extraction
One of the most important principles behind IndexerLabs is that indexing has two major problems:
- knowing what to index
- indexing it correctly
Those are related, but they are not the same.
The first problem is editorial. It involves significance, omission, phrasing, granularity, and structure.
The second problem is technical. It involves locating the right passages, verifying references, formatting the output, and delivering a reliable final index.
A weaker AI indexing workflow mixes these problems together. It generates a finished-looking index and leaves the user to clean it up afterward. That can be frustrating because the reviewer has to fix entry selection, phrasing, structure, locators, and formatting all at once.
IndexerLabs separates those stages.
With Checkpoints, the system can pause after candidate term generation and before full locator extraction. This gives the reviewer a high-leverage moment to improve the index while the entry list is still editable.
At that point, a reviewer can:
- remove weak headings
- add missing terms
- adjust phrasing
- broaden or narrow the index
- improve the quality of downstream extraction
After the reviewed list is approved, the system performs the extraction, verification, and delivery work against that improved set of entries.
That is a better model for human-in-the-loop AI indexing. The human reviewer is placed where their judgment has the greatest effect.
Locator Accuracy Is the Core Problem
An index is only useful if its locators are accurate.
A heading can sound plausible while pointing to the wrong page. A subentry can look elegant while sending readers to a passage that barely discusses the topic. A long list of weak locators can make an index harder to use than no index at all.
That is why AI for book indexing has to be built around verification.
IndexerLabs does not simply ask an AI model to output page numbers and trust the result. Locator claims are stored with supporting textual evidence. The system can check whether the claimed evidence actually appears on the page. When a case requires more interpretation, it can be escalated for additional adjudication.
This makes the index more transparent.
A reviewer should be able to see:
- what entry was claimed
- what page or passage supports it
- what text justified the locator
- whether the evidence is strong enough
- whether the entry should be accepted, revised, or rejected
That kind of evidence-based workflow is essential for serious AI book indexing.
Quick Check: Fast Review for AI-Generated Indexes
Even a strong AI indexing system should be reviewable.
Authors and publishers may want to spot-check the index before publication. Editors may want to inspect a sample of entries. A professional indexer may want to review the full output quickly.
Quick Check is designed for that kind of workflow.
The source page stays visible, the current locator is highlighted, and the reviewer can move through entries using simple keyboard controls. The goal is to reduce the friction of verification. Instead of searching through the document manually, the reviewer can see the claim, see the evidence, and approve or reject the entry.
This changes the character of review.
Instead of turning AI indexing into a slow cleanup job, Quick Check makes verification a focused editorial pass. Users can inspect a small sample, review a larger section, or move through a full index when the project calls for it.
For AI for book indexing to work in real publishing environments, review cannot be an afterthought. It has to be fast enough that people actually use it.
Embedded Word Indexes and AI Book Indexing
Many authors and publishers still work in Microsoft Word. That matters because Word supports embedded index markers, often called XE fields.
An embedded index works by placing index markers inside the document. When the index is updated, Word calculates the final page numbers from the document itself.
This is especially useful for AI for book indexing because page-number drift is one of the hardest last-mile problems.
If a manuscript changes after a static index is created, page numbers can shift. A paragraph may move. Formatting may change. A sentence may be added. In a static exported index, those changes can make the locators outdated.
With embedded DOCX support, IndexerLabs can insert index markers directly into the Word document. Word then generates the final page references from the actual document layout.
That means the model does not need to guess final page numbers. The AI determines what should be indexed and where the markers belong. Word handles the final pagination.
For authors and publishers working in Word, this creates a more flexible and production-safe indexing workflow.
AI for Book Indexing and Privacy
Manuscripts are sensitive.
Authors may be uploading unpublished books, scholarly monographs, confidential reports, theological works, legal materials, technical documents, or drafts still under contract. A serious AI book indexing tool has to treat manuscript privacy as a core requirement.
IndexerLabs is designed around private infrastructure. We do not send manuscript text to third-party AI APIs. Our models run on infrastructure we control, so book files remain inside the IndexerLabs processing environment, on our private servers in Germany.
For publishers, academic authors, and presses, this matters. AI for book indexing should make production easier without creating unnecessary data exposure.
Who Should Use AI for Book Indexing?
AI for book indexing is especially useful for people and organizations that need a professional index but do not want to create one manually from scratch.
IndexerLabs is designed for:
- academic authors
- university presses
- open-access publishers
- independent nonfiction authors
- editors managing book production
- scholarly societies
- theological publishers
- historians and biographers
- technical authors
- organizations publishing long-form research
It is especially useful for books where the index needs to capture ideas, arguments, names, themes, and conceptual structure.
What Kinds of Books Work Best?
IndexerLabs is best suited for nonfiction and scholarly books.
Strong use cases include:
Academic monographs
Academic books often contain dense arguments, proper nouns, technical vocabulary, primary texts, and recurring themes. AI can help create a structured draft index that the author or publisher can review.
Trade nonfiction
For nonfiction authors, an index improves usability and credibility. AI for book indexing can reduce the time required to create a useful back-of-book index.
History books
Historical works often contain many people, places, institutions, events, and themes. A good AI indexing workflow can help organize those references into a readable structure.
Theology and religious studies
Theological books may require subject indexing, name indexing, and scripture indexing. IndexerLabs supports complex indexing workflows, including scripture indexing.
Technical and professional books
Technical books need clear access points for concepts, methods, tools, case studies, and terminology. AI can help identify and organize those access points.
AI for Book Indexing vs. Traditional Indexing Software
Traditional indexing software is usually built for professional human indexers. These tools can be powerful, but they assume the human is doing the indexing work: selecting entries, writing subentries, assigning locators, and editing the final structure.
AI for book indexing serves a different role.
It helps generate the index itself.
That does not mean editorial review disappears. It means the first draft can be created much faster, and the reviewer can focus on improving the output rather than building everything from a blank page.
| Option | Best for | Limitation |
|---|---|---|
| Microsoft Word index tools | Manual embedded indexing | Slow for full books |
| Traditional indexing software | Professional indexers | Requires indexing expertise |
| Keyword extraction tools | Finding repeated terms | Produces term lists rather than finished indexes |
| Generic AI chatbots | Brainstorming possible entries | Weak long-document and locator reliability |
| IndexerLabs | AI-assisted professional book indexing | Best suited for nonfiction and scholarly books |
The goal is to make indexing faster, more affordable, and easier to review while preserving the features that make a real index useful.
How Much Does AI for Book Indexing Cost?
Traditional professional indexing can be expensive, especially for long or complex books. Costs often depend on page count, subject matter, density, schedule, and the experience of the indexer.
AI for book indexing can make the process more accessible.
IndexerLabs currently offers book indexing tiers starting at $99 per book for our subject indexing services, designed to be significantly more affordable than traditional manual indexing while still supporting structured entries, subentries, locator verification, review workflows, and publisher-friendly export.
For independent authors, small presses, open-access publishers, and academic writers, this can make the difference between skipping the index and producing a usability one.
Does an AI-Generated Index Still Need Review?
A good AI-generated index should be usable as a strong starting point, and in many cases it may require little editing. At the same time, publication workflows often demand review.
That review should be easy.
A useful AI book indexing tool should let authors and editors:
- inspect proposed entries
- remove weak headings
- add missing terms
- rename entries
- review locators
- check evidence
- adjust the final structure
- export the result cleanly
The point is not to shift the entire indexing burden onto the user. The point is to automate the heavy work while keeping the index transparent and editable.
What Makes a Good AI-Generated Book Index?
A good AI-generated book index should be judged by the same standards as any other index.
- Accurate: locators should point to real, useful discussions.
- Selective: entries should reflect meaningful topics, not raw word frequency.
- Readable: headings and subentries should be clear.
- Structured: broad topics should be organized with useful subentries.
- Consistent: names, terms, formatting, and phrasing should follow a coherent style.
- Reviewable: users should be able to inspect and revise the result.
- Exportable: the final output should fit the publishing workflow.
IndexerLabs was built around these standards.
Why IndexerLabs?
IndexerLabs is an AI book indexing platform designed for real manuscripts and real publishing workflows.
It combines:
- purpose-trained indexing models
- staged candidate discovery and refinement
- output length control
- automatic subentry generation
- evidence-based locator extraction
- structured verification
- Quick Check review
- Checkpoints for human-in-the-loop entry review
- embedded DOCX index support
- private infrastructure
- export formats designed for authors and publishers
The result is AI for book indexing that goes beyond keyword extraction.
IndexerLabs helps turn a finished manuscript into a structured, reviewable, professional back-of-book index.
Create your index with IndexerLabs.
Get Started