Candidate term discovery
Start from a model-generated list of possible terms instead of a blank page.
Professional indexers
IndexerLabs starts by generating a list of candidate terms to extract. You review that list, remove weak terms, add missing ones, and rephrase entries before extraction runs.
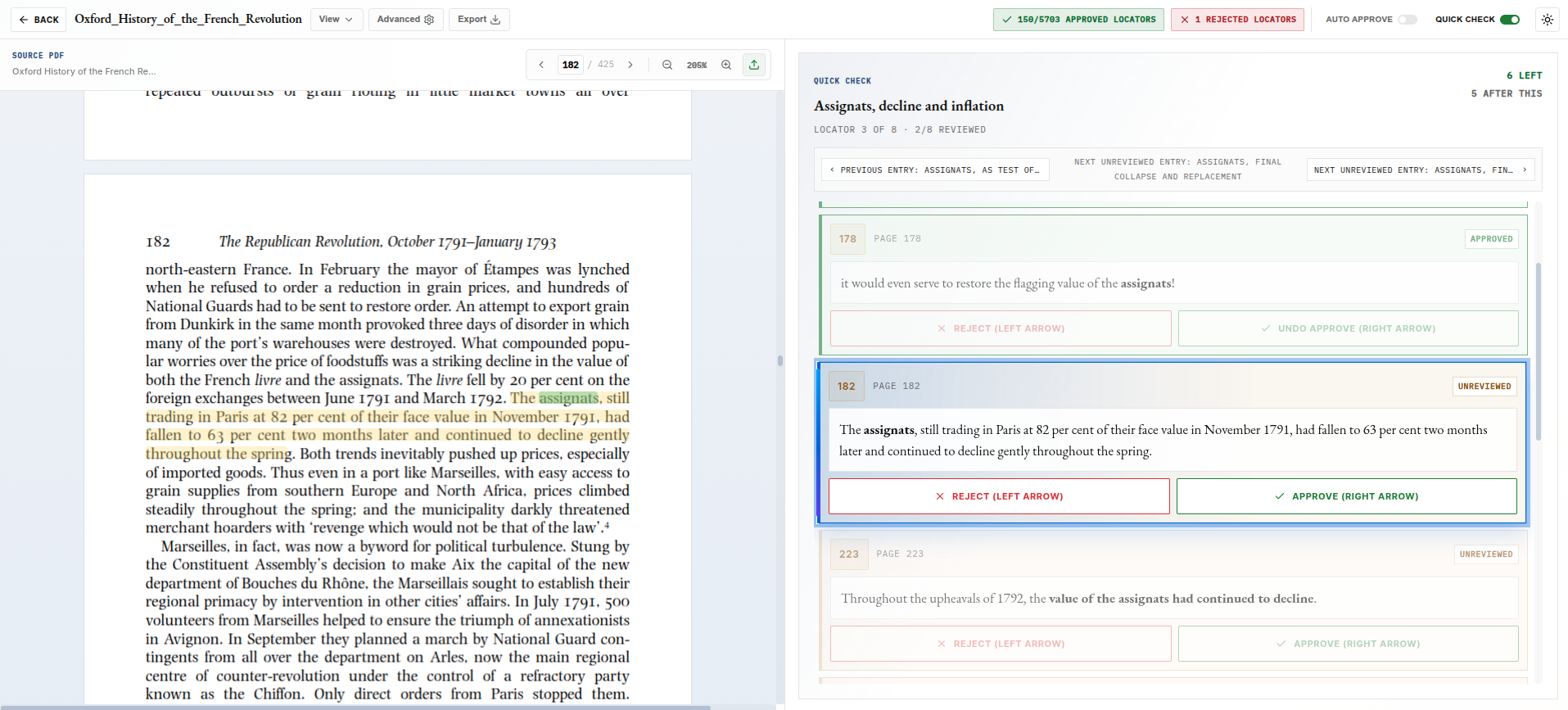
Start with a generated list of terms and headings to inspect before locator extraction.
Approve, delete, add, or rephrase terms while changes still have maximum leverage.
Only after review does the system extract source-grounded locators for the approved list.
Trusted by authors from:

































































Percentage of human-selected index topics retained by each model
Generic chatbots are not trained to make editorial indexing decisions. For this reason, IndexerLabs trained custom models on more than 1,000 real-world book indexes to ensure professional quality output.
In our 120-run benchmark on The Oxford History of the French Revolution, IndexLM-1.0 retained far more human-selected topics than general-purpose models when editing a publication-grade index.
We don't just give you an index. We give you a superpowered indexing workbench to rapidly verify, edit, and fine-tune your index, with unlimited AI-powered editing actions.
Traditional indexing timelines are measured in days. IndexerLabs can turn around a complete draft in under 2 hours.
We run all our AI systems on our private servers in Nuremberg, Germany. We do not send your data to any third party AI providers. We never train on your indexes or share them with third parties for any reason. You can delete all your data at any time.
Book indexing starts at $99/book, keeping professional indexing accessible without page-count surprises.
The first pass is not a finished index. It is a candidate list of terms and headings that IndexerLabs thinks may be worth extracting from the manuscript.
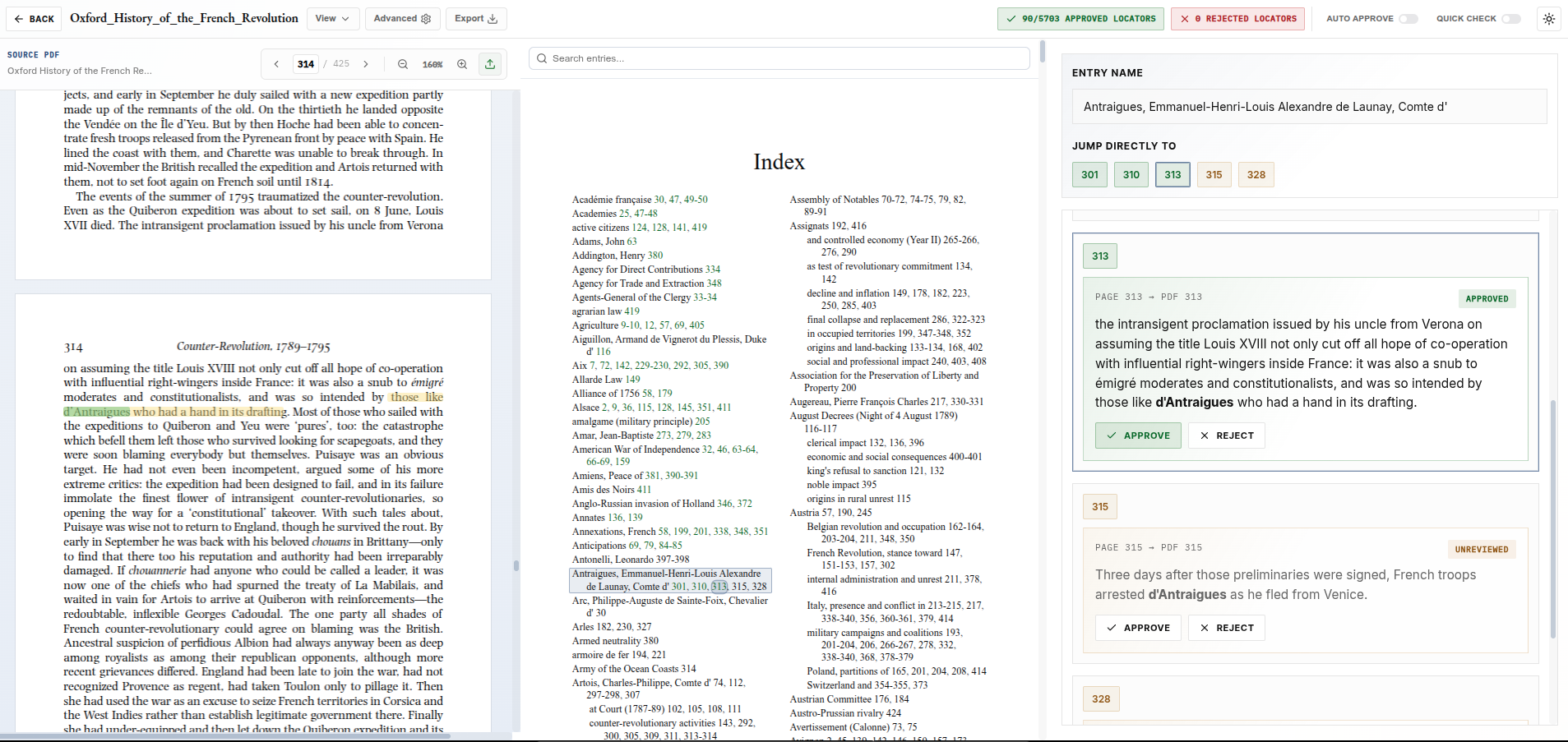
You review that list at Checkpoint: delete weak terms, add missing topics, rephrase headings, and shape the scope. Once the list is approved, IndexerLabs extracts locators and evidence for those terms.
Professional indexers should not have to repair a fully extracted draft built from a bad candidate set. The highest-leverage review happens before locators are created.
IndexerLabs separates those stages. First it proposes terms to extract. Then you review the list. Then the system extracts locators and evidence from the approved terms.
Use cases
Start from a model-generated list of possible terms instead of a blank page.
Approve, delete, add, and rephrase terms before locator extraction begins.
Generate locators and evidence from the reviewed term list.
Workflow
IndexerLabs reads the manuscript and proposes terms and headings that may be worth extracting.
Use Checkpoints to approve, remove, add, and rephrase terms before locator extraction.
Once the list is approved, IndexerLabs extracts locators and source evidence for those terms.
Use the editor, Quick Check, and export tools to finish the index.
Sources
FAQ
Yes, IndexerLabs employs the use of custom-trained Artificial Intelligence (AI) models to automate the process of indexing. We've custom-trained an AI model on 1,000 real-world indexes, which significantly improves accuracy and indexing taste. Read more about this model, IndexLM-1.0, in our blog post.
Yes, and significantly more so than other AI products. We host all our models on our own servers, so third parties never get your data. We do not send your data to any third parties like OpenAI or Google. Uploaded documents stay available for the index editor until you delete them from your dashboard. We never use your data for improving or training our product under any circumstances.
You can view our Oxford History of the French Revolution comparison side by side with its original printed index.
You can also view a shorter Neomania demo, using a book from Open Book Publishers.
We offer full refunds within 7 days of purchase.
To request a refund, please contact us at support@indexerlabs.com.
Subject book indexing starts at $99 per book, with $199 and $299 tiers available at checkout. Volume pricing is available for publishers, series, and recurring workflows.
Yes. While we aim to produce an elegant, high-quality index that adheres to your specifications on the first attempt, we allow for manual and AI-powered editing if there's anything you want to change, free of charge.
You can export your index into Microsoft Word (.docx), PDF (.pdf), plain text (.txt), or CDFX/IXML (used by professional indexing tools like Cindex).
Additionally, if you need any specific output formats tailored to your publisher's specifications, feel free to email us at support@indexerlabs.com at any time and we can help make a custom output format at no extra charge.
For support, questions, or feedback, please email us at support@indexerlabs.com. We typically respond within 48 hours.
After you upload a document, Subject Indexing usually takes 1-3 hours, depending on the length and complexity. In many cases, a 300-page book can be processed in under an hour.
Scripture Indexing usually finishes within 30 minutes of upload.
Use IndexerLabs to start from candidate terms, apply your judgment before extraction, and then review source-grounded locators.