Can ChatGPT Create a Book Index?
ChatGPT can help with parts of book indexing.
It can suggest candidate entries. It can help reorganize rough index text. It can explain the difference between main entries and subentries. It can look at a passage and propose possible topics a reader might want to find later.
But that is different from creating a reliable back-of-book index for a full manuscript.
A book index is not merely a generated answer. It is an edited navigational structure. A good index reflects the argument of the book, the vocabulary of the reader, the relative importance of topics, and the locations where those topics are meaningfully discussed.
A single prompt to ChatGPT may produce something that looks like an index. It may be alphabetical. It may contain page numbers. It may include plausible headings and subheadings. But the harder question is whether the index can be trusted as an index.
For most full-length nonfiction and academic books, the answer is no — not because AI is useless, and not simply because the manuscript is too long, but because indexing is not a one-shot reading task.
A professional index is built through iteration. The indexer reads, records, compares, revises, merges, splits, checks locators, removes weak references, and adjusts the structure until the index fits the book. Asking ChatGPT to create a finished index in one pass is like asking a human indexer to read an entire manuscript in one sitting, take no notes, mark no passages, make no revisions, and then recite the final index from memory.
That is not how indexing works.
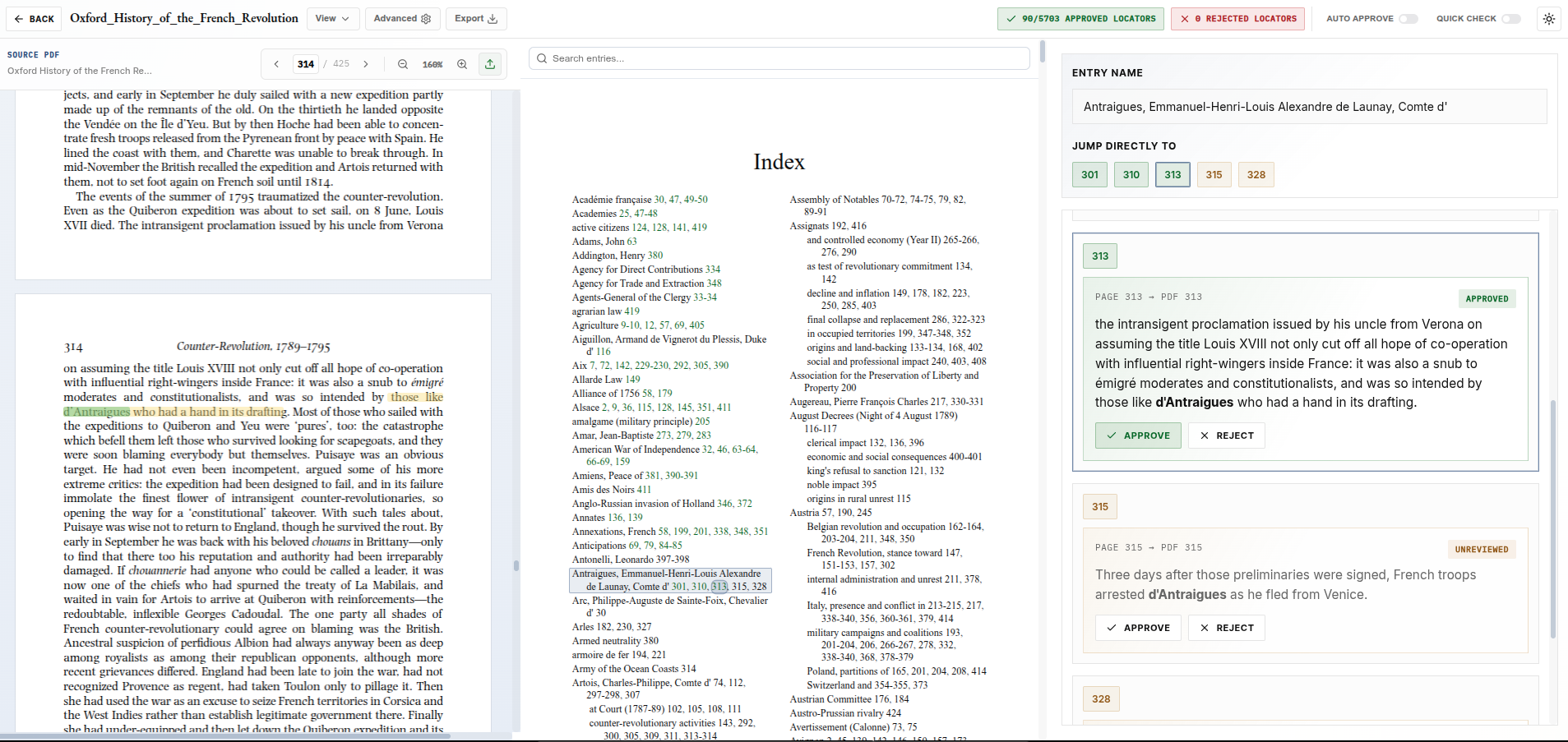
View a side-by-side comparison of a professional human index versus our AI-generated output for a 425-page scholarly volume.
View Oxford History Demo →Create your index with IndexerLabs.
Get StartedWhat ChatGPT can do for book indexing
It is useful to begin with what ChatGPT can do well.
ChatGPT is a language model, and book indexing involves language. Many indexing tasks require naming concepts, grouping related terms, summarizing distinctions, and recognizing patterns in text. Those are areas where ChatGPT can be helpful, especially when the task is limited and clearly framed.
For example, ChatGPT can help an author:
- identify possible index terms from a chapter;
- suggest subentries for a broad topic;
- reorganize a rough list of terms alphabetically;
- convert inconsistent phrasing into more consistent headings;
- explain indexing conventions;
- suggest “see” and “see also” references;
- help distinguish a broad entry from a narrower subentry;
- review a sample index entry for clarity.
These are real uses. They can save time.
If an author already knows that a chapter discusses “religious liberty,” “public education,” and “constitutional authority,” ChatGPT may be able to suggest possible subentries or help clarify the relationship among those topics.
If a draft index contains entries such as:
freedom of religion
religious freedom
religious liberty
church liberty
ChatGPT may help think through whether those should be merged, distinguished, or connected with cross-references.
But these are assistance tasks. They are not the same thing as indexing the whole book.
The problem begins when a tool that is useful for local editorial help is treated as if it can replace the entire indexing process.
Why a book index is not just generated text
A back-of-book index is easy to misunderstand because its final form looks simple.
It is alphabetical. It contains words and page numbers. It may occupy only a few pages at the end of the book. Compared with the manuscript itself, it looks small.
But that small object represents many decisions.
An index has to decide which topics matter, which names deserve entries, which mentions are too minor, how broad concepts should be divided, which terms readers are likely to look for, and where page references should point.
A weak index might say:
education, 12, 18, 19, 44, 77, 102, 118, 119, 203
That entry may be based on real occurrences of the word “education.” But it gives the reader little guidance. The reader still has to turn to each page to discover what kind of discussion appears there.
A stronger index might say:
education
classical curriculum and, 18–19
democratic citizenship and, 77
reform debates over, 102
religious instruction and, 203
This version does more than identify where a word appears. It organizes the book’s discussions into a usable structure.
That structure is not produced by word matching alone. It is produced by judgment.
This is why ChatGPT can generate index-shaped text without necessarily creating a good index. The output may have the external form of an index while missing the editorial process that makes an index useful.
Context length is not the same as an indexing workflow
A common explanation for ChatGPT’s indexing limitations is that a book is too long to fit into the prompt.
Sometimes that is true. Many manuscripts are long, and every model has practical limits. OpenAI’s own documentation notes that token capacity depends on the model and usage tier, even for high-capacity systems. (OpenAI Help Center)
But context length is only part of the issue.
Even when a model can accept a large amount of text, a context window is not the same thing as an indexing workflow.
A context window lets a model receive information. It does not by itself create a stable editorial process for recording decisions, revisiting earlier judgments, comparing entries across chapters, verifying locators, pruning weak references, and exporting a finished index.
Indexing requires more than access to the manuscript. It requires controlled revision over the manuscript.
If the system decides in chapter 2 to index a topic under “religious liberty,” it should not later create separate entries for “freedom of religion,” “religious freedom,” and “church liberty” unless those distinctions are meaningful. If the system treats one passing mention of John Adams as too minor to index, it should apply a comparable standard elsewhere. If a broad topic receives subentries in one part of the index, similar broad topics need to be handled with comparable structure.
Those are not merely memory problems. They are workflow problems.
A large context window may help the model see more of the book at once. It does not guarantee that the model will preserve indexing decisions consistently across the whole work.
The problem of context rot
The practical failure is often what we might call context rot.
Context rot does not mean the model has literally forgotten everything outside a small window. It means that as the task becomes longer and more complex, the model’s ability to preserve, compare, and enforce editorial decisions becomes less reliable.
In a short passage, ChatGPT may identify candidate index terms reasonably well. In a single chapter, it may produce a plausible list of topics. Across a full manuscript, the problem changes.
The system must now maintain a large set of decisions:
- which topics are important enough to index;
- which names are central and which are incidental;
- which terminology should be preferred;
- which page references are substantial;
- which entries should be merged;
- which broad topics require subentries;
- which cross-references help the reader;
- how long the index should be;
- whether the final structure is balanced.
This is difficult to do in a single generation.
The model may overemphasize material near the end of the prompt. It may preserve some early decisions but not others. It may generate headings that sound appropriate but are not used consistently. It may produce a long list of entries without distinguishing central discussions from passing mentions. It may create page references that look plausible but are not grounded in the manuscript.
The result is not always obviously bad. That is part of the risk.
A poor AI-generated index can look orderly. It can be alphabetized. It can contain page numbers. It can appear professional at a glance. But when a reader uses it, the weaknesses become visible: missing topics, weak locators, duplicated headings, inconsistent terminology, and long undifferentiated page lists.
In indexing, plausibility is not enough.
The human analogy
Imagine asking a professional indexer to work this way:
Read the entire book in one sitting. Do not take notes. Do not mark pages. Do not build a draft. Do not revise earlier entries. Do not check page references. Do not merge duplicates. Do not create a second pass. When you finish reading, immediately recite the final index.
No publisher would treat that as a serious indexing process.
A human indexer does not create an index by memory alone. The indexer builds a working structure while reading. Candidate entries are recorded. Page references are attached. Entries are revised. Some headings are renamed. Some are removed. Some are split into subentries. Some are consolidated under broader terms. Page ranges are checked. The index is pruned and balanced.
That process matters because the index changes as the book comes into view.
Early in a manuscript, “education” may look like a simple recurring topic. Later, after seeing the whole book, the indexer may realize that “education” should be divided into classical curriculum, civic formation, religious instruction, and reform debates. The better index emerges from revision, not from first-pass recall.
One-shot ChatGPT indexing has the same weakness as the imaginary human workflow. It asks for a finished editorial object without the editorial process that produces one.
The issue is not whether AI can help with indexing. It can.
The issue is whether the AI system is allowed to work like an indexer: recording, comparing, revising, checking, pruning, and preparing the result for publication.
Indexing is an editing loop
A good index is not written once.
It is built through an editing loop.
The process usually begins with candidate topics. Some are obvious: major people, places, institutions, theories, events, and concepts. Others emerge more slowly. A recurring theme may become important only after several chapters. A term that seemed central early in the book may turn out to be incidental. A broad heading may need to be divided. A minor name may not deserve an entry after all.
This is why revision is not a secondary part of indexing. It is part of the work itself.
Consider a rough entry:
democracy, 11, 26, 42, 43, 44, 78, 109, 144, 145, 146, 201
This may be a reasonable first draft. But it is not yet a finished entry.
After review, it might become:
democracy
constitutional limits on, 42–44
elite suspicion of, 78
popular sovereignty and, 144–146
religious arguments about, 201
The improvement does not come from finding the word “democracy” more times. It comes from understanding the different discussions grouped under that term.
The indexer has to ask:
- Are these pages all about the same thing?
- Should some locators be removed?
- Should several pages be treated as a range?
- Does the topic need subentries?
- Are the subentries parallel?
- Would a reader understand what each subentry means?
- Is this entry too broad?
- Is it too narrow?
- Does it overlap with another entry?
That is the work a one-shot prompt does not reliably perform.
The first draft of an index is not the index. The edited structure is the index.
Why page numbers are especially difficult
Page numbers are one of the hardest parts of AI book indexing.
In an index, a page number is not a decoration. It is a claim.
A page should not be included merely because a term appears there. It should be included because the page contains a discussion that would be useful to a reader looking up that topic.
This distinction is easy to miss.
Suppose a book mentions “natural law” on six pages. On one page, the phrase appears in a list of concepts. On another, it appears in a quotation. On two pages, the author develops an argument about natural law and political authority. On another, the term appears in a footnote. On the final page, the author compares natural law to another theory.
A weak system may index all six pages.
A better system asks which pages matter.
The finished entry may include only the pages where the concept is substantively discussed. It may also create subentries if the discussions differ:
natural law
political authority and, 88–90
rival theories of, 142–144
ChatGPT may be able to discuss this distinction in the abstract. The challenge is applying it consistently across a full manuscript with hundreds or thousands of possible locators.
A reliable indexing workflow needs locator support. It needs a way to ground page references in the actual document, check whether the topic is meaningfully discussed, and allow the reviewer to inspect questionable references.
Without that, the page numbers may be plausible but untrustworthy.
Why uploading the whole book is not enough
It is tempting to think that the solution is simply to upload the whole manuscript and ask for an index.
That may improve the situation, but it does not solve the indexing problem.
Uploading the manuscript gives the model access to text. It does not automatically provide:
- stable page mapping;
- chapter-aware structure;
- persistent candidate entry tracking;
- consistent heading normalization;
- duplicate detection;
- locator verification;
- subentry balancing;
- index length control;
- pruning of weak references;
- export into a publication workflow.
Those are separate tasks.
A manuscript is not just a mass of text. It has pages, chapters, sections, notes, headings, front matter, back matter, quotations, captions, and sometimes multiple kinds of references. An index has to interpret that structure.
For example, a name in the bibliography should usually not be treated the same way as a name discussed in the body of the book. A term in a chapter title may be more important than the same term in a passing footnote. A topic developed across three pages may deserve a page range. A topic mentioned in a caption may or may not deserve inclusion, depending on the book.
A generic upload-and-prompt workflow tends to flatten these distinctions.
Indexing requires document understanding, but it also requires editorial control over the output.
Can ChatGPT create subentries?
ChatGPT can suggest subentries when given a topic and relevant passages.
For example, if given several passages about education, it may propose subentries such as:
education
civic formation and
curriculum and
religious instruction and
reform debates over
That can be useful.
But subentry generation is not only a naming task. Subentries have to correspond to actual locators. They have to divide the topic in a way that reflects the book. They have to be concise, parallel, and useful to the reader. They also have to avoid creating distinctions that sound elegant but are not supported by the text.
A model can generate plausible subentry labels. The harder task is integrating those subentries into a complete index.
For a broad entry, the system must decide:
- which locators belong under the main heading;
- which locators should be grouped together;
- whether a subentry is too broad;
- whether two subentries overlap;
- whether the wording is parallel;
- whether the entry has become too fragmented;
- whether the reader will understand the distinctions.
That requires iterative review.
This is another reason one-shot indexing fails. A model may produce subentries, but it has not necessarily performed the editorial work needed to make those subentries reliable.
Can ChatGPT make an embedded Word index?
ChatGPT can explain how embedded Word indexes work. It can describe XE fields. It can show examples of index field syntax. It can help an author understand the difference between a static back-of-book index and an embedded index.
But creating an embedded Word index is not primarily a text-generation task.
An embedded index requires placing index markers at specific locations inside the document. Those markers must correspond to the passages being indexed. They must be inserted without damaging the document. They must use consistent headings and subheadings. Then Microsoft Word can generate the index from those markers.
That is a document-processing workflow.
A chatbot may describe the process, but it does not, by itself, reliably parse the manuscript, decide where markers belong, insert them into the .docx, preserve formatting, and prepare the document for production.
This matters because embedded indexing is often more useful than a static index when the manuscript is still changing. If page numbers may shift, embedded markers allow the index to be regenerated after layout changes.
For AI book indexing, the important task is not simply producing a block of index text. It is connecting index decisions to locations in the document.
What a real AI book indexing workflow needs
A reliable AI book indexing workflow should not depend on a single prompt.
It should include a series of controlled steps.
1. Parse the manuscript
The system has to understand the document as a document: pages, chapters, sections, headings, notes, and other structural features.
2. Identify candidate entries
The system should identify possible people, places, concepts, events, institutions, works, and recurring themes that may belong in the index.
3. Distinguish substantial discussion from passing mention
A term appearing on a page is not enough. The page must contain a meaningful discussion that would help the reader.
4. Normalize headings
Related terms need to be merged, separated, or connected with cross-references. The vocabulary of the index should be consistent.
5. Create subentries where needed
Broad entries should be divided into useful subentries when a simple locator list would be too vague.
6. Verify locators
Page references should be grounded in the manuscript and available for review.
7. Prune weak entries
The system should remove trivial names, incidental mentions, duplicated concepts, and noisy locators.
8. Balance the final index
The index should fit the book’s length, genre, density, and audience.
9. Produce reviewable output
Authors and editors should be able to inspect the index, revise entries, and check questionable locators.
10. Export for publication
The final index should be available in a format that fits the publishing workflow, whether that means a static index, a Word-compatible output, or an embedded index.
This is the difference between using AI as a text generator and using AI as part of an indexing system.
ChatGPT vs an AI book index generator
The difference between ChatGPT and an AI book index generator is not simply that one uses AI and the other does not. Both may use language models.
The difference is workflow.
ChatGPT is a general-purpose conversational system. It can answer questions, generate text, summarize material, and assist with many writing tasks. But book indexing requires a specialized process around the manuscript.
An AI book index generator should be designed around indexing decisions:
| Task | ChatGPT one-shot prompt | AI book indexing workflow |
|---|---|---|
| Read the manuscript | May process uploaded or pasted text depending on limits | Parses the manuscript as a structured document |
| Identify topics | Can suggest plausible terms | Tracks candidate entries across the book |
| Handle page references | May be unreliable without grounding | Connects locators to document locations |
| Remove passing mentions | May do inconsistently | Applies filtering and review |
| Create subentries | Can suggest labels | Groups locators into structured entries |
| Merge duplicates | May catch obvious overlaps | Normalizes headings across the index |
| Revise | Requires manual prompting | Built into the workflow |
| Export | Usually returns generated text | Supports publication-oriented output |
The central question is not whether AI can produce index-like text.
The question is whether the system supports the editorial operations that make an index trustworthy.
Does a ChatGPT-generated index need human review?
Yes.
Any AI-generated index should be reviewed before publication. This is especially true for a ChatGPT-generated index because the output may include weak locators, missing topics, duplicated headings, or plausible but unsupported structure.
Human review should ask:
- Are the book’s central topics represented?
- Are important people, places, concepts, and events included?
- Are minor mentions over-indexed?
- Are broad topics divided into useful subentries?
- Are duplicate headings merged?
- Are page references accurate?
- Are cross-references helpful?
- Does the index match the book’s terminology?
- Is the index proportionate to the book?
This review is not a sign that AI has failed. Review is part of indexing.
The value of an AI system is that it can give the reviewer a structured draft rather than a blank page. But the draft must be good enough to review. If the index is merely a long list of plausible entries, the reviewer may spend more time repairing it than it would have taken to build the index properly.
When ChatGPT may be enough
There are limited cases where ChatGPT may be sufficient.
For a short document, a private report, a classroom handout, or an informal reference guide, a ChatGPT-generated topic list may be adequate. If the stakes are low and the document is short enough for manual checking, the result may be useful.
It may also be enough when the goal is not a true back-of-book index but a rough navigation aid.
But for a published nonfiction book, academic monograph, edited volume, theological work, legal text, technical manual, or serious long-form manuscript, the requirements are higher.
Readers expect the index to work. Publishers expect page references to be accurate. Authors expect the index to reflect the argument of the book. A generic one-shot output is usually not enough.
What to do instead
A better approach is to treat AI indexing as an editorial workflow.
The workflow should allow the system to:
- read the manuscript structurally;
- identify candidate topics;
- attach locators to real passages;
- separate substantial discussions from passing mentions;
- create and revise subentries;
- normalize headings;
- prune weak entries;
- verify locators;
- produce reviewable output;
- export the result for publication.
This approach is slower than a single prompt, but it is much closer to the way indexing actually works.
It also produces a more useful division of labor.
AI can help with the repetitive and large-scale parts of indexing: scanning, candidate discovery, grouping, locator support, and draft construction. Human review can focus on judgment: emphasis, terminology, missing topics, conceptual nuance, and final approval.
That is a more realistic use of AI.
The goal is not to ask a chatbot to remember the book. The goal is to build a structured index from the book.
Create a reviewable AI-generated book index with IndexerLabs
IndexerLabs is built for AI book indexing, not one-shot prompt generation.
The workflow is designed around the parts of indexing that matter most: manuscript structure, meaningful entries, useful subentries, locator support, pruning, review, and publication-ready output.
If you are comparing ChatGPT, human indexing, and AI indexing by budget, see our guide to how much does book indexing cost.
That distinction matters because a book index is not a summary and it is not a list of keywords. It is a navigational tool for readers.
ChatGPT can help with pieces of the process. But a reliable back-of-book index requires more than a large context window and a plausible answer. It requires an indexing workflow that can record decisions, revise them, verify them, and prepare the result for publication.
A good index is not simply generated.
It is built.
FAQ
Can ChatGPT create a book index?
ChatGPT can help create parts of a book index, such as candidate entries, possible subentries, or reorganized index text. But a single ChatGPT prompt is usually not enough to create a reliable back-of-book index for a full manuscript.
Can ChatGPT index a full book?
ChatGPT may be able to process large amounts of text depending on the model, plan, and file workflow, but processing text is not the same as indexing a book. A full book index requires consistent headings, accurate locators, subentries, pruning, and review.
Why does one-shot ChatGPT indexing fail?
One-shot indexing fails because a book index is an iterative editorial structure. It requires recording decisions, revising entries, checking page references, merging duplicates, removing passing mentions, and balancing the final index. A single generated answer usually cannot do all of that reliably.
What is context rot in AI book indexing?
Context rot is the degradation that happens when a model’s ability to preserve and apply decisions becomes less reliable across a long, complex task. In book indexing, this can lead to inconsistent headings, missing topics, duplicated entries, weak locators, and uneven subentries.
Can ChatGPT generate page numbers for an index?
ChatGPT may generate page numbers if given page-aware text, but those page numbers should not be trusted without verification. In an index, every locator is a claim that the topic is meaningfully discussed on that page.
Is ChatGPT good for back-of-book indexing?
ChatGPT is useful for bounded indexing tasks, such as brainstorming entries or suggesting subentries from selected passages. It is less reliable as a complete back-of-book indexing system because indexing requires document grounding, locator verification, revision, and export.
What is the difference between ChatGPT and an AI book index generator?
ChatGPT is a general-purpose conversational AI system. An AI book index generator should be a specialized workflow for parsing a manuscript, identifying entries, assigning locators, creating subentries, pruning weak references, and preparing an index for review and publication.
Does a ChatGPT-generated index need human review?
Yes. A ChatGPT-generated index should be carefully reviewed before publication. The reviewer should check missing topics, weak locators, duplicate headings, subentry structure, terminology, and overall usefulness to the reader.
Can ChatGPT create an embedded Word index?
ChatGPT can explain embedded Word indexes and XE fields, but creating an embedded Word index requires placing markers at the correct locations inside a .docx document. That is a document-processing workflow, not just a text-generation task.
What should I use instead of a one-shot ChatGPT prompt?
Use an AI book indexing workflow that parses the manuscript, identifies candidate entries, verifies locators, creates subentries, removes weak references, supports review, and exports the final index in a publication-ready format.
Create your index with IndexerLabs.
Get Started