AI Book Index Generator: What It Can and Cannot Do
An AI book index generator sounds like a simple tool.
Upload a manuscript. Click a button. Receive an alphabetical index with page numbers. Drop it into the back of the book and move on.
That is the easy version of the problem, and is also the version that fails.
A back-of-book index is not just a list of words that appear in a manuscript. It is a reader-facing map of the book’s ideas. A good index tells readers where the important discussions are. It filters out passing mentions. It groups related topics. It creates useful subentries. It chooses headings a reader would actually look for. It gives page references that lead somewhere meaningful.
That means an AI book index generator has to do more than generate text. It has to make indexing decisions.
A weak generator produces something that looks like an index. A strong generator produces something an author, editor, or publisher can actually review, trust, and use.
This guide explains what an AI book index generator is, where generic tools fall short, and what a serious indexing workflow should do before an index is ready for publication.
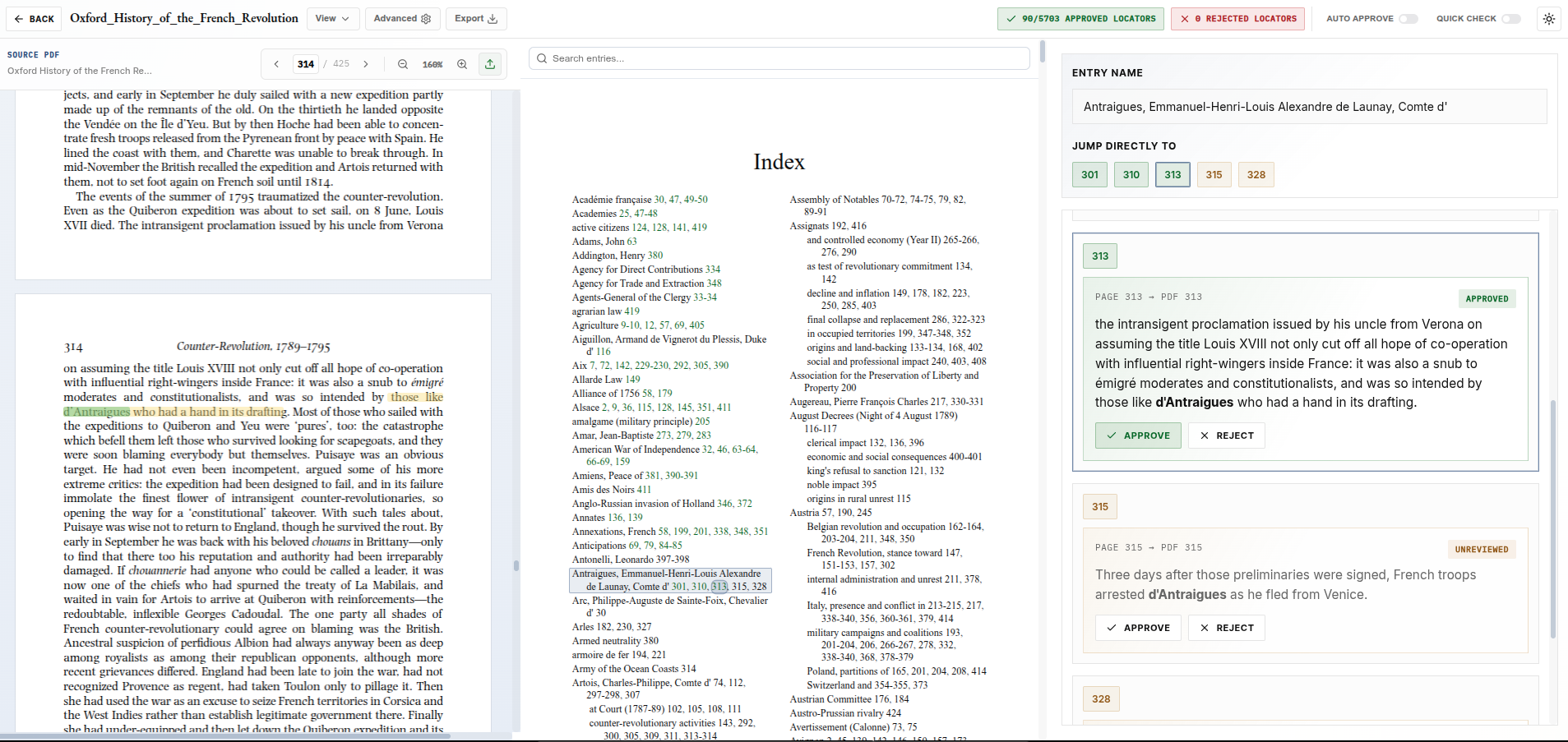
View a side-by-side comparison of a professional human index versus our AI-generated output for a 425-page scholarly volume.
View Oxford History Demo →Create your index with IndexerLabs.
Get StartedWhat is an AI book index generator?
An AI book index generator is software that uses artificial intelligence to create or assist with a back-of-book index.
At the simplest level, it may scan a manuscript and identify important names, concepts, places, events, organizations, and technical terms. A more advanced system goes further. It creates main entries, proposes subentries, assigns page references, removes weak mentions, and prepares the index for review.
A finished book index usually includes:
- Main entries for important people, concepts, places, events, institutions, works, and themes
- Subentries that divide large topics into more specific discussions
- Locators, usually page numbers, that point readers to relevant passages
- Cross-references, such as “see” and “see also”
- Editorial judgment about what belongs in the index and what should be omitted
The last part is the hardest.
Finding words is easy. Deciding whether those words belong in the index is not.
For example, a weak generator might produce this:
education, 12, 18, 19, 44, 77, 102, 118, 119, 203
That entry is not useless, but it is not very helpful either. The reader has no way to know what kind of discussion happens on each page.
A stronger index might look like this:
education
classical curriculum and, 18–19
democratic citizenship and, 77
reform debates over, 102
religious instruction and, 203
The second version does more than point to pages. It tells the reader what they will find.
That is the difference between a term list and an index.
Why generating a book index is harder than it looks
Book indexing looks mechanical from the outside.
A book contains terms. An index contains terms. So it is natural to assume that the task is mostly extraction.
But a real index is not a concordance. It does not list every occurrence of every important-looking word. It selects the discussions that matter.
A word can appear many times and still be a poor index entry. Another concept may appear only a few times and still be central to the argument. A person may be named in passing on twenty pages but discussed meaningfully on only three. A theme may run throughout a chapter without being named in exactly the same words each time.
This is especially important for academic and nonfiction books. Readers often use the index to answer specific questions:
- Where does the author discuss this person?
- Where is this concept developed in detail?
- Where does this historical event become important to the argument?
- Where is this doctrine, law, theory, or technical term explained?
- Which pages are worth turning to, rather than merely containing the word?
A book index is a tool for navigation. If it sends readers to the wrong places, it fails.
AI book index generator vs keyword extraction
The most common mistake is confusing an AI book index generator with a keyword extractor.
A keyword extractor can identify repeated phrases, proper nouns, and statistically unusual terms. That can be useful as a starting point. It can help build a candidate list. It can reveal names and concepts that might be worth indexing.
But keyword extraction does not solve the indexing problem.
A keyword extractor might see that the phrase “natural law” appears on pages 14, 38, 39, 80, 111, and 204. It may then create:
natural law, 14, 38, 39, 80, 111, 204
That might be right. It might also be wrong.
A real index has to ask better questions:
- Is page 14 a definition, or just a passing mention?
- Are pages 38–39 part of one sustained discussion?
- Does page 80 discuss natural law, or only quote someone who uses the phrase?
- Should the entry be “natural law” or should it be grouped under a broader topic?
- Does the entry need subentries?
- Are there related terms that need cross-references?
- Is the final locator list useful to the reader?
A weak AI system stops at extraction.
A serious AI book index generator uses extraction as one stage in a larger workflow.
What a weak AI book index generator does
A weak generator usually fails in predictable ways.
It may still produce a polished-looking result. That is part of the danger. The output can look index-like without being a good index.
It indexes words instead of ideas
The system identifies repeated words and turns them into entries. It does not understand whether the topic is important, whether the discussion is substantial, or whether the wording matches how a reader would search.
It includes too many passing mentions
A passing mention is not always worth indexing. If a name appears in a list, a footnote, or a throwaway comparison, it may not deserve a locator.
Too many weak locators make an index frustrating to use. The reader turns to a page expecting a real discussion and finds only a sentence fragment.
It creates flat entries
A broad topic with twelve page numbers usually needs subentries. Without subentries, the index forces readers to guess.
democracy, 11, 26, 42, 43, 44, 78, 109, 144, 145, 146, 201
That entry may be accurate, but it is not well organized. A better index explains what kind of discussion happens across those pages.
It invents or misplaces page numbers
For an index, locator accuracy is not optional. If the page numbers are wrong, the index fails at its most basic job.
Generic AI systems can produce convincing but unsupported references. That is not acceptable for publication.
It misses implicit topics
A book may discuss a concept without using the same phrase every time. A weak generator may miss those discussions because it is too literal.
It duplicates related entries
The same topic may appear under several names:
American Revolution
Revolutionary War
War of Independence
United States Revolution
Sometimes those should be separate. Often they should be merged, normalized, or connected with cross-references.
It gives no review path
A generated index should not be a black box. Authors and editors need to inspect entries, check locators, remove weak terms, rename headings, and adjust structure.
If the tool cannot support review, it is not ready for serious indexing work.
What a strong AI book index generator should do
1. Read the manuscript at book scale
The generator needs to understand the whole book, not just isolated passages.
A useful index reflects the shape of the book: its chapters, recurring arguments, major people, central concepts, and important examples. If the system reads only small chunks without a broader view, the final index can become scattered.
Book-scale reading helps the system distinguish between a term that appears often and a topic that actually matters.
2. Identify candidate entries
The system should identify possible index entries across the manuscript:
- people
- places
- organizations
- events
- concepts
- technical terms
- works cited or discussed
- institutions
- laws, doctrines, theories, or methods
- recurring themes
At this stage, breadth matters. The system should notice possible entries without assuming that every candidate belongs in the finished index.
3. Separate substantial discussions from passing mentions
This is one of the core indexing decisions.
A page belongs in a locator list when it contains a meaningful discussion of the topic. A page does not automatically belong because the word appears there.
For example, suppose a book mentions “John Adams” on ten pages. Some pages may discuss Adams’s political thought. Others may mention him only in a list of founders. A good index should not treat those pages equally.
4. Create useful subentries
Subentries are not decoration. They are how an index handles broad topics.
A flat entry like this is hard to use:
capitalism, 9, 12, 44, 45, 46, 82, 113, 140, 141, 188, 221
A better version gives the reader structure:
capitalism
industrial labor and, 44–46
religious criticism of, 188
rural markets and, 82
theories of, 113
The point is not simply to make the index look professional. The point is to reduce friction for the reader.
A strong generator should detect when a topic has enough locators to need subentries and should propose subentries that reflect real differences in the text.
5. Merge duplicates and normalize headings
Books often refer to the same thing in multiple ways. A strong index generator should help unify those references.
For names, this may mean converting “John Adams” to:
Adams, John
For concepts, it may mean choosing the clearest heading and routing related phrases toward it.
For example:
wage labor. See labor, wage
factory work. See labor, industrial
or:
labor
factory work and, 44–48
wage systems and, 91–94
The right structure depends on the book. The important point is that the generator should not leave the reader with a pile of near-duplicates.
6. Verify locators
Locator verification is where many AI-generated indexes break.
A serious AI book index generator should not merely output a page number because the model thinks it sounds right. It should ground each locator in the manuscript. Ideally, the reviewer should be able to see why the page was included.
This matters because a bad locator damages trust. One wrong page number may be a small annoyance. A pattern of weak or false locators makes the whole index suspect.
7. Prune the index
More entries do not automatically make a better index.
A bloated index can be harder to use than a selective one. It overwhelms readers with minor names, incidental terms, and long locator strings.
A strong generator should remove weak entries, combine duplicates, reduce noisy locators, and keep the final index proportionate to the book.
That last word matters: proportionate.
A 150-page trade nonfiction book does not need the same index as a 500-page academic monograph. A dense technical book needs different coverage than a memoir. A theology book may need scripture references. A legal or classical text may need citation indexing. The index should fit the book.
8. Produce reviewable output
AI can speed up indexing, but the final index still needs to be inspectable.
A good generator should let authors and editors review:
- which entries were included
- which entries were omitted
- which locators support each entry
- which broad topics received subentries
- which entries were merged
- which terms need cross-references
- whether the index is too long or too short
The goal is not to hide the process. The goal is to make review faster.
9. Export in publication-ready formats
A generated index is only useful if it fits the publishing workflow.
Authors and publishers may need plain text, Word, PDF, IXML/CDFX, or an embedded Word index. In some workflows, the index is a static back-of-book file. In others, especially with Microsoft Word, embedded index markers are more useful because page numbers can update when the document changes.
The format is not a minor detail. It determines whether the index can actually move into production.
Can ChatGPT be used as a book index generator?
ChatGPT can help with parts of the indexing process.
It can brainstorm possible entries. It can explain indexing concepts. It can help reorganize a sample entry. It can suggest subentries for a topic if given relevant passages.
But a generic chatbot is usually not enough to generate a reliable back-of-book index for a full manuscript.
The problem is not that chatbots are useless. The problem is that book indexing requires a level of grounding, consistency, and locator control that a single prompt does not provide.
For full-length books, several problems appear:
- The model may not handle the entire manuscript consistently.
- It may miss topics buried in the middle of the book.
- It may invent page numbers.
- It may include pages where the term appears only in passing.
- It may fail to create useful subentries.
- It may produce inconsistent headings.
- It may over-index minor names and under-index central ideas.
- It may not provide a clean way to verify each locator.
That is why specialized AI book indexing tools exist.
The task is not just text generation. It is document analysis, editorial selection, locator verification, index structuring, and export.
AI book index generator vs book indexing software
Traditional book indexing software and AI book index generators are related, but they are not the same thing.
Traditional indexing software is usually built for professional indexers. It helps manage entries, sort headings, format page ranges, create cross-references, and export a finished index. But the human indexer still does the intellectual work of reading the book and deciding what belongs in the index.
An AI book index generator tries to help with the earlier and harder stages: identifying candidate topics, proposing entries, creating subentries, assigning locators, and preparing a structured draft.
Here is the difference:
| Tool type | What it usually does | Main limitation |
|---|---|---|
| Microsoft Word index tools | Lets users manually mark index entries with field codes | Slow for full books |
| Professional indexing software | Helps human indexers manage, sort, edit, and format indexes | Requires indexing expertise |
| Keyword extraction tools | Finds repeated or statistically important terms | Produces term lists, not finished indexes |
| Generic AI chatbots | Generates plausible headings or sample entries | Weak locator grounding and long-document consistency |
| AI book index generators | Attempts to create a structured draft index from the manuscript | Quality depends on workflow, verification, and review |
The best workflow may combine these categories.
AI can generate a structured draft. Human review can improve it. Professional export formats can move it into production.
The point is not to pretend that every indexing decision is mechanical. The point is to make the indexing process faster, more reviewable, and more accessible.
Example: keyword list vs AI-generated book index
Consider a book that discusses religion and public life.
A keyword-oriented system might produce:
religion, 12, 14, 17, 33, 44, 45, 46, 81, 82, 120, 121, 177, 203
This is not enough. The entry is broad, and the page list is undifferentiated.
A stronger index might produce:
religion
civic education and, 120–121
constitutional limits on, 44–46
public morality and, 81–82
reform movements and, 177
toleration debates and, 33
The second version is more useful because it understands that “religion” is not one discussion. It is a cluster of discussions.
The same issue appears with people.
A weak system might produce:
Adams, John, 6, 9, 12, 14, 19, 44, 88
A stronger index asks whether each page is meaningful. It may reduce the entry to:
Adams, John
constitutional thought of, 44
correspondence with Jefferson, 88
early political career of, 12–14
This is what an AI book index generator should aim for. Not more terms. Better navigation.
How to review an AI-generated book index
An AI-generated index should be reviewed like any other index.
The review does not have to mean rebuilding the index from scratch. The value of a good generator is that it gives the reviewer a structured draft. But the reviewer should still ask basic quality questions.
Are the major topics represented?
Start with the book’s central argument. Are the people, concepts, events, and themes that matter most actually present?
A missing central topic is more serious than a few extra minor entries.
Are there too many passing mentions?
Look at a sample of entries. Do the locators point to real discussions, or just pages where a term happens to appear?
If many locators are weak, the index needs pruning.
Do broad entries have subentries?
Any major topic with a long list of page numbers may need subentries. Long undifferentiated strings are hard to use.
Are duplicate entries merged?
Check for repeated forms:
United States
U.S.
America
American republic
Some distinctions may be meaningful. Others may need consolidation or cross-references.
Are names formatted consistently?
Names should follow a consistent pattern. Personal names usually need inversion:
Adams, John
not:
John Adams
unless the publisher’s style says otherwise.
Are cross-references useful?
Cross-references should guide readers, not clutter the index. A “see also” reference should point to a real related entry.
Is the index the right length?
A short, simple book should not have a massive index. A dense scholarly book may require more coverage. The index should feel proportionate to the book’s complexity, audience, and purpose.
Can each locator be checked?
The reviewer should be able to verify that a page reference points to a meaningful passage. If the tool cannot support that, review becomes much harder.
Who should use an AI book index generator?
An AI book index generator can be useful for several kinds of users.
Nonfiction authors
Many nonfiction authors need an index but do not know where to start. A generator can provide a structured draft instead of a blank page.
Academic authors
Academic authors often face indexing at the worst possible moment: after the manuscript is done, during production, when deadlines are tight. AI book indexing can reduce the burden by creating a draft that the author can review.
Small publishers
Small presses often need professional-looking indexes but may not have the budget or schedule for a traditional indexing process on every title. A generator can make indexing more feasible.
Open-access publishers
Open-access books are often built for use, teaching, and citation. A good index makes them more navigable. AI indexing can help more open-access books include reader-friendly back matter.
Editors and production teams
Editors can use generated indexes as reviewable drafts, especially when the alternative is last-minute manual indexing under deadline pressure.
Authors revising an existing index
A generator can also help diagnose a weak index: missing topics, flat entries, duplicated headings, or long locator strings that need subentries.
When not to rely on an AI book index generator alone
AI indexing is not equally suited to every situation.
Some books require especially careful expert review:
- legal treatises
- medical texts
- scientific reference works
- highly technical manuals
- books with complex multilingual terminology
- books with strict publisher style requirements
- works where mistakes could materially mislead readers
In these cases, AI may still be useful. But it should be part of a reviewed workflow, not treated as an unquestioned final authority.
The same is true for dense scholarly books. A good AI-generated draft can save time, but the author or editor may still need to adjust terminology, emphasis, and conceptual structure.
What to look for in an AI book index generator
Not every generator is built for real indexing.
When evaluating a tool, look past the demo output and ask how the system handles the hard parts.
A serious AI book index generator should support:
- full-manuscript analysis
- meaningful candidate entry discovery
- filtering of passing mentions
- useful subentry generation
- consistent entry naming
- locator grounding or verification
- duplicate merging
- index length control
- review workflows
- export formats for publication
- manuscript privacy
- examples of real generated indexes
Why reviewability matters
A black-box index is hard to trust.
An author should be able to inspect the result. An editor should be able to remove weak entries. A publisher should be able to check formatting. A reviewer should be able to verify that locators point to real discussions.
This is not a weakness of AI book indexing. It is the condition that makes AI book indexing useful.
The strongest workflow is not:
AI generates the index. Everyone accepts it.
The stronger workflow is:
AI creates a structured draft.
The system grounds and organizes the output.
The reviewer checks the important decisions.
The final index is exported for publication.
That is a practical publishing workflow.
It respects the fact that indexing is editorial work while still using AI to remove much of the repetitive burden.
Why embedded indexes matter
Most AI book index generators return a separate index file.
That can work well when the book’s pagination is final. But many authors and publishers are working in Microsoft Word before final layout. In that environment, page numbers can change when the text is revised, margins shift, fonts change, or front matter is adjusted.
An embedded index solves a different problem.
In Microsoft Word, index entries can be stored as embedded markers inside the document. These markers tell Word what to include in the index. When the document changes, Word can regenerate the index using the updated page numbers.
For AI book indexing, that is especially valuable.
Instead of asking AI to guess final page numbers, the system can decide what should be indexed and where the markers belong. Then Word calculates the final page numbers from the actual document.
That makes the index more resilient during revision.
For authors and publishers still working in Word, embedded indexing can be the difference between a static draft and a production-friendly workflow.
The future of AI book index generators
The future of AI book indexing is not a chatbot prompt that returns an alphabetical list.
The future is workflow.
The best systems will combine language models with document parsing, page-level grounding, editorial selection, subentry generation, pruning, verification, and export. They will treat the index as a structured publishing object, not a block of generated prose.
That is the direction the category has to move.
An index has one job: help readers find what matters.
An AI book index generator is valuable only when it serves that purpose.
Create an AI-generated book index with IndexerLabs
IndexerLabs is built for AI book indexing, not keyword extraction.
The workflow is designed around the parts of indexing that matter most: meaningful entries, useful subentries, locator reliability, review, and publication-ready output.
If you have a nonfiction manuscript, academic monograph, theological work, historical study, technical book, or long-form research project that needs an index, IndexerLabs can help create a structured draft faster than building one manually from scratch.
If budget is part of the decision, see our guide to book indexing cost.
A good index makes a book easier to use.
An AI book index generator should do the same.
FAQ
What is an AI book index generator?
An AI book index generator is software that uses artificial intelligence to create or assist with a back-of-book index. A strong generator identifies important topics, creates main entries and subentries, assigns locators, and produces an index that authors or editors can review.
Can AI generate a book index?
Yes, AI can generate a book index when it is used in a workflow designed for indexing. The quality depends on how the system handles manuscript context, locator accuracy, subentries, duplicate terms, passing mentions, and human review.
Is an AI book index generator the same as keyword extraction?
No. Keyword extraction finds repeated words or phrases. Book indexing requires editorial judgment: deciding which topics matter, how they should be named, which pages deserve locators, and how broad topics should be organized.
Can ChatGPT create a book index?
ChatGPT can help brainstorm entries or reorganize sample index text, but a generic chatbot is usually not enough for a reliable full-book index. A serious index needs page-aware locators, long-document consistency, verification, and reviewable output.
How accurate are AI-generated book indexes?
AI-generated indexes can be accurate when the workflow verifies locators and allows review. They are less reliable when generated from a single prompt without grounding, page checks, or editorial controls.
Does an AI-generated book index need human review?
Usually, yes. Human review helps ensure that the index matches the book’s argument, terminology, and audience. The advantage of an AI book index generator is that the reviewer starts from a structured draft instead of a blank page.
What should I look for in an AI book index generator?
Look for full-manuscript analysis, useful subentries, filtering of passing mentions, locator verification, duplicate merging, index length control, review tools, privacy, and export formats that fit your publishing workflow.
Who should use an AI book index generator?
AI book index generators are useful for nonfiction authors, academic authors, small publishers, open-access publishers, editors, and production teams that need a structured back-of-book index faster than a fully manual process.
Can an AI book index generator create subentries?
A strong AI book index generator should create subentries for broad topics. Subentries help readers understand what kind of discussion appears on each page instead of forcing them to interpret long strings of page numbers.
Can AI create an embedded Word index?
Some AI indexing workflows can support embedded Word indexes by inserting index markers into a .docx document. This can be useful when page numbers may change during revision or formatting. IndexerLabs offers .docx embedding.
Create your index with IndexerLabs.
Get Started