Of all the ways an AI-generated index can fail, none is more damaging than a bad locator. A heading may look perfectly reasonable while sending the reader to entirely the wrong page. The locator is the index’s core promise — it tells readers where a discussion can actually be found. When that promise breaks, so does the index.
Locator accuracy, then, is not simply a matter of model fluency. It is not enough for a system to assert that a topic appears on page 6. That claim must be grounded in the text of page 6 itself, and it must undergo verification before it enters the final index.
How we solved this problem
To make locator claims verifiable, we don’t allow the model to respond in unconstrained prose. We require structured JSON output, which forces the model to separate its claim into explicit, checkable fields: the normalized index entry, the claimed page number, and the exact textual evidence drawn from that page.
Index form and page text are often not the same thing. A page may contain the phrase “John Adams,” while the correct index entry reads “Adams, John.” A reliable verification system needs both — the editorial form of the entry and the textual form as it appears in the source.
Compare these two outputs:
{
"entry": "Adams, John",
"page": 6
}
This is insufficient. The model has made a locator claim but supplied nothing that can be checked.
{
"entry": "Adams, John",
"page": 6,
"matched_text": "John Adams argued that the measure would endanger the union.",
"match_phrase": "John Adams"
}
This is a much better output. The model is no longer simply asserting that the topic belongs on page 6, but it is rather exposing the exact text on which that locator depends.
Two-step verification
Most first-pass verification is handled deterministically in Python. Once the model returns a structured record, Python loads the claimed page and checks whether the supporting text actually appears there. The logic is as follows:
- The model proposes an entry and locator.
- The model provides the exact supporting text for that locator.
- Python checks whether that text occurs on the claimed page.
- If it does, the locator passes first-stage verification.
- If it doesn’t, it is flagged for further review.
The more interesting cases arise when the relationship between index entry and page text isn’t reducible to a simple string match. A page may contain only “Adams” or “John Adams” rather than the normalized form “Adams, John” — and a mechanical checker will reject the claim even though the page is plainly referring to the right person.
Not every deterministic rejection, therefore, reflects a genuine indexing error. Some arise from OCR artifacts, punctuation differences, or line-break issues. Others involve a more interpretive question: does a partial match like “Adams” actually ground the normalized entry “Adams, John”?
When such cases arise, we escalate them to a separate LLM review system. This model does not generate entries, as its role is only adjudicative. It examines the structured output, the claimed page, and the relevant text, then determines whether a rejection reflects a real hallucination, a formatting mismatch, or valid evidence that a simple string check couldn’t capture. The second-stage reviewer can verify the contextual claim from the first stage: does this page’s use of “Adams” legitimately support the entry “Adams, John”? If the answer is yes, then the entry is allowed to continue onwards in the pipeline. If the answer is no, then the entry is discarded and the error sent to the developers.
In order to decrease the rate of hallucinations within our review model, we turn the model’s temperature down to 0. Temperature is the setting that controls how much randomness the model uses when choosing among possible outputs. At higher temperatures, a model is more likely to produce varied or inventive responses; at 0, it is pushed toward the most likely answer supported by the input. That makes it better suited to a narrow verification task, where the goal is not originality but consistent judgment grounded in the page text and the structured claim under review.
The result is a pipeline that is mechanical and auditable at its core, while still handling difficult edge cases with judgment. Across our 20,000 benchmarked locators, no locator error has survived this dual-verification workflow.
We use use this same approach for our Scripture Indexing service, which allows us to attain and maintain 99.8% overlap with our human counterparts for scripture index backtests.
Making human review faster
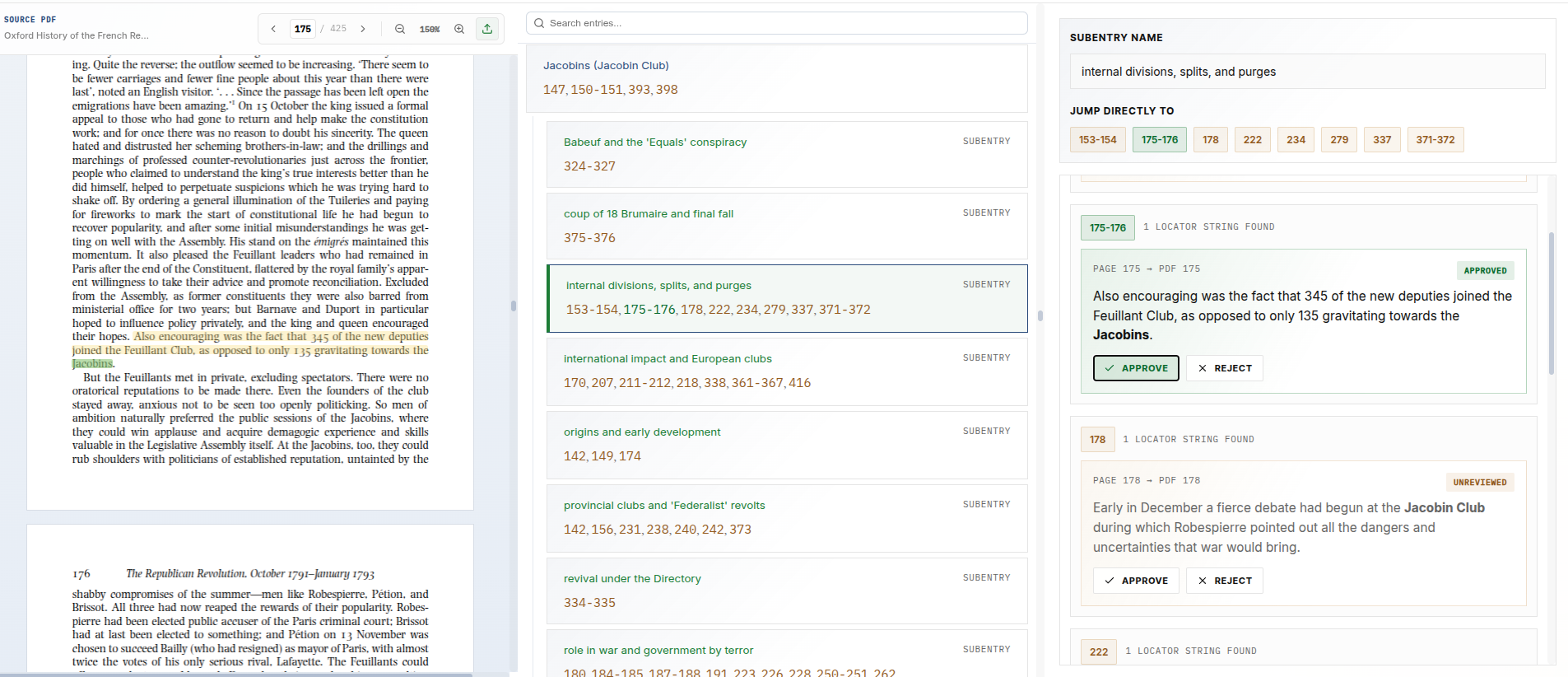
While structured output enables automated verification, it also makes human review more efficient. Because every locator claim is stored alongside its entry, page number, and supporting text, questionable cases can be surfaced directly in a review interface rather than buried in raw model output.
A good review system shouldn’t force an editor to reconstruct the model’s reasoning from scratch. It should show, clearly and immediately, what was claimed, where it was cited, and what evidence was offered in support.
Structured output also makes human review more efficient. Because every locator claim is stored alongside its entry, page number, and supporting text, questionable cases can be surfaced directly in a review interface rather than buried in opaque model output.
That gives editors something much better than a bare assertion. They can see exactly what was claimed, where it was cited, and what evidence was offered in support. Instead of reconstructing the model’s reasoning after the fact, they can evaluate the claim directly.
That is the real advantage of the system. It does not merely improve locator accuracy; it makes locator decisions transparent. Every accepted reference can be traced back to textual evidence, verified mechanically, and reviewed by a human when necessary. The result is an indexing workflow that is faster, more reliable, and auditable.